Your Fairseq-trained model might have more embedding parameters than it should.
How a bug in reading SentencePiece vocabulary files causes some Fairseq-trained models to have up to 3k extra parameters in the embedding layer.
 Embedding matrix
Embedding matrix
This blog post documents the bug I came across while using the Fairseq toolkit to train the models for my LREC-COLING 2024 paper.
TL;DR: Some NLP models trained on Fairseq since version 0.10.0 (e.g. LASER, CamemBERT, UmBERTo) have 3xd extra parameters in the embedding layer (where d=320, 768, 1024 is the embedding dimension), meaning that up to 0.002% of model parameters are unaccounted for. This results from a bug in reading Fairseq Dictionary objects from files, which adds duplicate SentencePiece special tokens with wrong indices to the vocabulary. While some work-arounds have been implemented, I propose a bug fix in this PR. Whether or not this is a serious issue with major effects on computation cost and model performance remains to be seen.
Discovering the bug
When loading LASER’s SentencePiece (SPM) vocabulary during preprocessing (using fairseq-preprocess), I got an error telling me that the dictionary file had duplicates (the special tokens <s>, </s> and <unk>), and that I should add a #fairseq:overwriteflag to ignore them. But when I did that, I noticed a mismatch during training (using fairseq-train) between my actual vocabulary size (54,001) and the vocabulary size expected by the model’s embedding layer (54,004). So, I went hunting for the source of the problem…
Expected behaviour (Fairseq < 0.10.0)
By default, when loading a vocabulary from a file, a Fairseq Dictionary instance is first created by adding 4 special tokens in this order: the beginning-of-sequence symbol <s>, the padding <pad> symbol, the end-of-sequence </s> symbol, and the unknown symbol <unk>. Then, all the entries from the file are appended to the Dictionary. After preprocessing, the output dictionary file (dict.txt) will not contain any of the special symbols.
A Dictionary object uses the following attributes to store tokens:
indices: a dict with symbols (or tokens) as keys and their indices as valuessymbols: a list of symbolscounts: a list of the number of occurences of each symbol
When a new symbol is added to the dictionary, it is appended to the symbols list, and its index and count are updated. If the symbol already exists in the dictionary, only its count is updated (incremented).
Note: Depending on the task, more special tokens could be added after the symbols from the disctionary file, e.g. the
<mask>token for masked languange models (MLMs) or language ID tokens for multilingual models.
The number of Dictionary symbols is then used as vocabulary size of the subsequent tokenizer and embedding size of the subsequent model. For example, here are the attributes for the RoBERTa-base model:
>>> model = AutoModel.from_pretrained("FacebookAI/roberta-base")
>>> model.embeddings.word_embeddings
Embedding(50265, 768, padding_idx=1)
>>> tokenizer = AutoTokenizer.from_pretrained("FacebookAI/roberta-base")
>>> tokenizer.vocab_size
50265
>>> len(tokenizer.vocab.items())
50265
>>> tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>']
>>> tokenizer.all_special_ids
[0, 2, 3, 1, 50264]
Current behaviour (Fairseq >= 0.10.0)
From version 0.10.0 onwards, an overwrite argument was added (see Commit) to explicitly deal with duplicate symbols. Their entry in the vocabulary file should contain #fairseq:overwrite, otherwise a “duplicate” error will be raised at runtime.
Here’s the add_symbol function in fairseq/fairseq/data/dictionary.py:
def add_symbol(self, word, n=1, overwrite=False):
"""Adds a word to the dictionary"""
if word in self.indices and not overwrite:
idx = self.indices[word]
self.count[idx] = self.count[idx] + n
return idx
else:
idx = len(self.symbols)
self.indices[word] = idx
self.symbols.append(word)
self.count.append(n)
return idx
This function is responsible for adding the symbols to the Dictionary. It has an overwrite argument that is set to True when the corresponding line in the file has #fairseq:overwrite. Rather than testing if word in self.indices and overwrite, it is currently testing if word in self.indices and not overwrite, which makes it ignore the case where the symbol should actually be overwritten and proceeds to duplicate them instead. So, rather than its count being incremented, the symbol is appended to the symbols list, and its index is changed in the indices dict. This results in a Dictionary with duplicate symbols and incorrect indices.
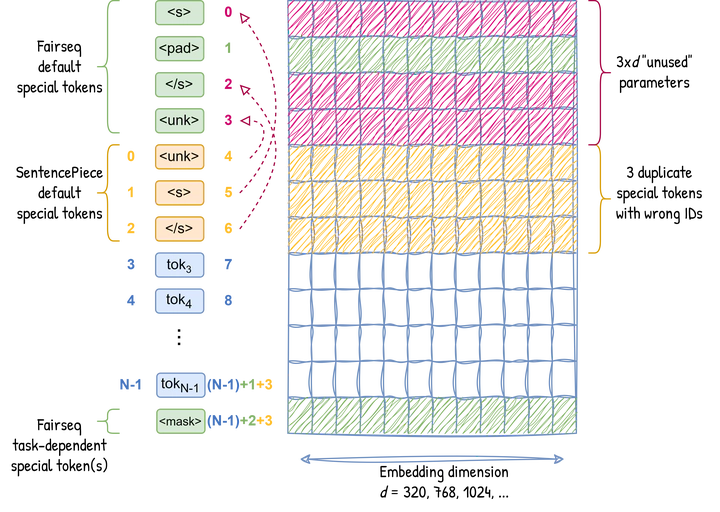
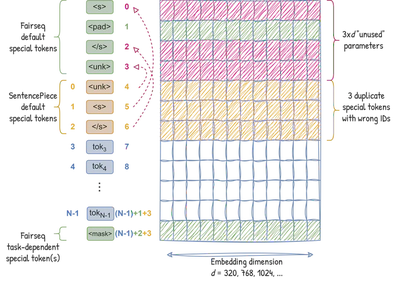
In general, only the special symbols will be affected because the Dictionary is initialised with 4 default special tokens, and an SPM dictionary has 3 of them by default: <s>, </s> and <unk> (see SentencePiece documentation).
Note: These duplicate special tokens are not counted in the number of special tokens
self.nspecial, which is set during initialisation.
As a result, the vocabulary has 3 extra tokens, and the embedding matrix 3 extra rows. This means that an embedding layer of size d has 3xd extra weight parameters! The following figure illustrates it:
And this is what I encountered with the LASER models. For example, LASER2:
>>> model['params']
{'num_embeddings': 50004, 'padding_idx': 1, 'embed_dim': 320, 'hidden_size': 512, 'num_layers': 5, 'bidirectional': True, 'left_pad': True, 'padding_value': 0.0}
>>> len(model['dictionary'].items())
50001
>>> list(model['dictionary'].items())[:10]
[('<s>', 5), ('<pad>', 1), ('</s>', 6), ('<unk>', 4), ('▁', 7), (',', 8), ('.', 9), ('s', 10), ('a', 11), ('i', 12)]
and LASER3 which uses the same tokenizer (tested with the Swahili model):
>>> model['model']['embed_tokens.weight'].size()
torch.Size([50004, 1024])
Specifically, the Fairseq Dictionary object is initialised with 4 special tokens <s>, <pad>, </s> and <unk> with indices 0, 1, 2, 3. Meanwhile, LASER’s SPM model was trained with a vocabulary size of N = 50,000 (indices numbered from 0 to N-1). By default, this vocabulary starts with the 3 special tokens <unk>, <s> and</s>. So, after loading the SPM vocabulary file, the final Dictionary will have at index 1 the special token <pad> that was not included by SPM, which will make the vocabulary size N+1 = 50,001. However, because of the bug, the 3 SPM special tokens are duplicated at positions 4, 5, 6, making the total vocabulary size N+4 = 50,004. Furthermore, the indices of <s>, <pad>, </s> and <unk> in the resulting Dictionary become 5, 1, 6, 4 instead of 0, 1, 2, 3.
Note: When using
fairseq-preprocess, the resulting dictionary file (dict.txt) will skip the first 4 special symbols as expected, but will still contain the 3 duplicate ones.
Some existing work-arounds
Others have encountered this issue and implemented ways to work around it. For example, the LASER team resets and corrects the indices of the special tokens when initialising their SentenceEncoder object:
self.bos_index = self.dictionary["<s>"] = 0
self.pad_index = self.dictionary["<pad>"] = 1
self.eos_index = self.dictionary["</s>"] = 2
self.unk_index = self.dictionary["<unk>"] = 3
Another solution adopted for other Fairseq-trained models is to consider the original overwritten tokens as “unused” special tokens: <s>NOTUSED, </s>NOTUSED and <unk>NOTUSED (e.g. in Transformers’s CamembertTokenizer). This is the case for the following models:
>>> model = AutoModel.from_pretrained("almanach/camembert-base")
>>> model.embeddings.word_embeddings
Embedding(32005, 768, padding_idx=1)
>>> auto_tokenizer = AutoTokenizer.from_pretrained("almanach/camembert-base") # same as CamembertTokenizerFast
>>> auto_tokenizer.vocab_size
32005
>>> len(auto_tokenizer.vocab.items())
32005
>>> auto_tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED', '<unk>NOTUSED']
>>> auto_tokenizer.all_special_ids
[5, 6, 4, 1, 32004, 0, 2, 32005]
>>> camembert_tokenizer = CamembertTokenizer.from_pretrained("almanach/camembert-base")
>>> camembert_tokenizer.vocab_size
32000
>>> len(camembert_tokenizer.vocab)
32005
>>> camembert_tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED', '<unk>NOTUSED']
>>> camembert_tokenizer.all_special_ids
[5, 6, 3, 1, 32004, 0, 2, 4]
>>> model = AutoModel.from_pretrained("almanach/camembert-large")
>>> model.embeddings.word_embeddings
Embedding(32005, 1024, padding_idx=1)
>>> auto_tokenizer = AutoTokenizer.from_pretrained("almanach/camembert-large") # same as CamembertTokenizerFast
>>> auto_tokenizer.vocab_size
32005
>>> len(auto_tokenizer.vocab.items())
32005
>>> auto_tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED', '<unk>NOTUSED']
>>> auto_tokenizer.all_special_ids
[5, 6, 3, 1, 32004, 0, 2, 4]
>>> camembert_tokenizer = CamembertTokenizer.from_pretrained("almanach/camembert-large")
>>> camembert_tokenizer.vocab_size
32000
>>> len(camembert_tokenizer.vocab)
32005
>>> camembert_tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED', '<unk>NOTUSED']
>>> camembert_tokenizer.all_special_ids
[5, 6, 3, 1, 32004, 0, 2, 4]
>>> model = AutoModel.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
>>> model.embeddings.word_embeddings
Embedding(32005, 768, padding_idx=1)
>>> tokenizer = AutoTokenizer.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
>>> tokenizer.vocab_size
32005
>>> len(tokenizer.vocab.items())
32005
>>> tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED', '<unk>NOTUSED']
>>> tokenizer.all_special_ids
[5, 6, 3, 1, 32004, 0, 2, 4]
- and UmBERTo-uncased:
>>> model = AutoModel.from_pretrained("Musixmatch/umberto-commoncrawl-uncased-v1")
>>> model.embeddings.word_embeddings
Embedding(32005, 768, padding_idx=1)
>>> tokenizer = AutoTokenizer.from_pretrained("Musixmatch/umberto-commoncrawl-uncased-v1")
>>> tokenizer.vocab_size
32005
>>> len(tokenizer.vocab.items())
32004
>>> tokenizer.all_special_tokens
['<s>', '</s>', '<unk>', '<pad>', '<mask>', '<s>NOTUSED', '</s>NOTUSED']
>>> tokenizer.all_special_ids
[5, 6, 3, 1, 32004, 0, 2]
>>> tokenizer.convert_ids_to_tokens([4])
['<unk>NOTUSED']
All these models have the 3 duplicate tokens. However, you’ll notice that only LASER and UmBERTo-uncased have an explicit mismatch between the number of embeddings a.k.a. the tokenizer’s vocabulary size (tokenizer.vocab_size), and the actual number of items in the vocabulary (len(tokenizer.vocab.items())).
Note: This list is far from exhaustive, but the chances are that models that were built on them have the same embedding layer dimensions and similar special tokens.
So, how bad is the damage?
The models we’ve discussed have 3 extra tokens by default, which are the default SPM special tokens. The following table shows that the number of extra parameters ranges from 960 to 3072, which is roughly 0.002% of all model parameters.
| Model | Model params | Vocab size | Embed dim | Duplic. tokens | Extra params | % Extra params |
|---|---|---|---|---|---|---|
| LASER2 | 44,615,936 | 50,004 | 320 | 3 | 960 | 0.002 |
| LASER3 | 152,002,561 | 50,004 | 1,024 | 3 | 3,072 | 0.002 |
| CamemBERT-base | 110,621,952 | 32,005 | 768 | 3 | 2,304 | 0.002 |
| CamemBERT-large | 336,661,504 | 32,005 | 1,024 | 3 | 3,072 | 0.001 |
| UmBERTo-cased | 110,621,952 | 32,005 | 768 | 3 | 2,304 | 0.002 |
| UmBERTo-uncased | 110,621,952 | 32,005 | 768 | 3 | 2,304 | 0.002 |
If the SPM vocabulary is created with all 4 special tokens, the number of extra parameters with be 4xd, which could go up to 4096 extra parameters (for d=1024)! Maybe it’s not that big of a deal because this number is rather insignificant compared to the millions of parameters in the whole model (0.001 to 0.002%), or is it? Still, no waste is better than a little waste…
While the CamemBERT and UmBERTo solution considers those duplicate special tokens as NOTUSED, you may have noticed that I keep referring to the extra parameters as “unused”, with quotes. That’s because I’m not sure that they actually are unused. I’m really curious to know what effect they have (if any) on:
- computation cost,
- training time, and
- model performance at inference.
Perhaps some brave soul could look into that? 😉
Also, I might just be nitpicking, but I find it problematic for models of the same tokenizer family to have different indices for special tokens. For example, CamemBERT-large, UmBERTo-cased and UmBERTo-uncased have the same indices, which are different from CamemBERT-base’s, which are all different from RoBERTa-base’s.
Luckily, this issue is not in all Fairseq-trained models. Here is a non-exhaustive list of models which are not affected (loaded using Transformers 4.38.2):
- RoBERTa
- Twitter RoBERTa
- XLM-RoBERTa
- GottBERT
- BART
- mBART
- XLM-MLM
- XGLM 564M
- NLLB distilled 600M
Furthermore, I pinpointed the source of the bug to version 0.10.0 of Fairseq onwards. So, most branches in Fairseq at the original time of posting (16th March 2024) have this issue, including the main branch. The branches that have the pre-bug version of the Dictionary class are:
bi_trans_lmblockbertclassic_seqeval(infairseq/fairseq/dictionary.py)lightningnaive_beamsearchseq_tasksimulastsharedtaskxlmr_benchmark
Fixing the bug
My first intuition was just to remove the not from if word in self.indices and not overwrite in the add_symbol function, but I quickly realised it wasn’t enough. The solution had to satisfy 3 major conditions:
- no more duplicate special tokens with incorrect indices for future models
- consistency with the expected behaviour from versions before
0.10.0 - backward-compatibility with models that were already trained with this bug
So, I submitted in this Pull Request with my proposed changes.
In order to satisfy the first 2 conditions, the SPM dictionary file (.cvocab) should have:
#fairseq:overwriteflags along with the duplicate special tokens:
<unk> 1 #fairseq:overwrite
<s> 1 #fairseq:overwrite
</s> 1 #fairseq:overwrite
▁ 1
, 1
...
- or simply, none of the duplicate special tokens:
▁ 1
, 1
...
In order to keep the duplicate tokens for backward-compatibility (condition 3), #fairseq:duplicate flags should be used. This is what I did for my LASER model:
<unk> 1 #fairseq:duplicate
<s> 1 #fairseq:duplicate
</s> 1 #fairseq:duplicate
▁ 1
, 1
...
Takeaways
Some NLP models trained on Fairseq since version 0.10.0 (e.g. LASER, CamemBERT, UmBERTo) have 3xd extra parameters in the embedding layer (where d=320, 768, 1024 is the embedding dimension), meaning that up to 0.002% of model parameters are unaccounted for. This results from a bug in reading Fairseq Dictionary objects from files, which adds duplicate SentencePiece special tokens with wrong indices to the vocabulary. While some work-arounds have been implemented, I propose a bug fix in this PR. Whether or not this is a serious issue with major effects on computation cost and model performance remains to be seen.
If you’ve made it this far, I have 3 things to say:
- Thank you for reading! 😊
- I urge you to check whether your Fairseq-trained models (or any models built on/fine-tuned from them) are affected by this. If you’re training new models, I advise you to check the Fairseq version and branch you’re using, and to ensure that your SentencePiece vocabulary file does not have special tokens (or uses the right flags to deal with them accordingly).
- I welcome your comments, especially if you have any insights about whether the extra “unused” parameters have an impact on model training and performance!
Lydia Nishimwe
PhD Student
I am a PhD student currently working on the neural machine translation of user-generated content (e.g. social media posts).